





SolidityBench by IQ was launched as the first benchmark to evaluate LLMs in Solidity code generation. Available on Hugging Face, it features two innovative benchmarks, NaïveJudge and HumanEval for Solidity, designed to assess and rank the proficiency of AI models in generating smart contract code.
Developed by IQ’s BrainDAO as part of its upcoming IQ Code suite, SolidityBench is used to refine its own EVMind LLMs and compare them to general-purpose and community-created models. IQ Code aims to provide AI models suitable for generating and auditing smart contract code, meeting the growing need for secure and efficient blockchain applications.
As IQ said CryptoSlateNaïveJudge offers a novel approach by tasking LLMs with implementing smart contracts based on detailed specifications derived from audited OpenZeppelin contracts. These contracts constitute a benchmark for accuracy and efficiency. The generated code is evaluated against a reference implementation using criteria such as functional completeness, adherence to Solidity best practices and security standards, and optimization effectiveness.
The evaluation process relies on advanced LLMs, including different versions of OpenAI’s GPT-4 and Claude 3.5 Sonnet as impartial code reviewers. They evaluate code based on rigorous criteria, including implementation of all key features, handling of edge cases, error handling, appropriate use of syntax, and the overall structure and maintainability of the code. code.
Optimization considerations such as gas efficiency and storage management are also evaluated. Scores range from 0 to 100, providing a comprehensive assessment of functionality, security and effectiveness, reflecting the complexity of professional smart contract development.
Which AI models are best for developing strong smart contracts?
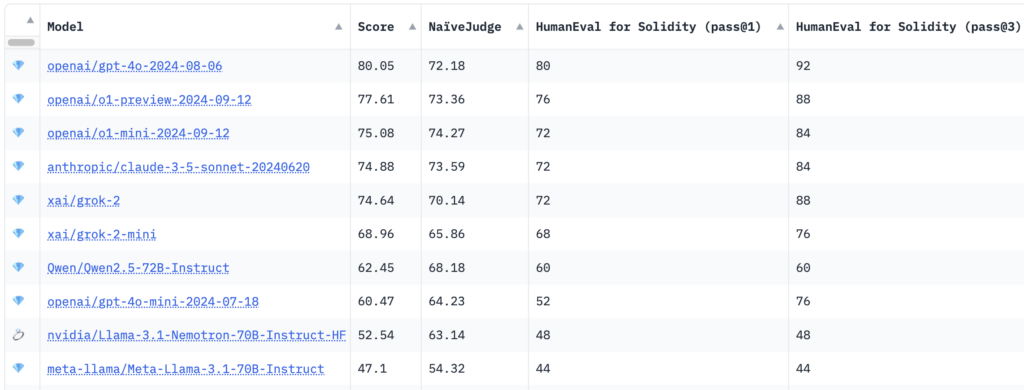
Benchmarking results showed that OpenAI’s GPT-4o model achieved the highest overall score of 80.05, with a NaïveJudge score of 72.18 and HumanEval pass rates for Solidity of 80%. at pass@1 and 92% at pass@3.
Interestingly, new reasoning models like OpenAI’s o1-preview and o1-mini were beaten to first place, with scores of 77.61 and 75.08, respectively. Models from Anthropic and 10 with 52.54.
According to IQ, HumanEval for Solidity adapts OpenAI’s original HumanEval benchmark from Python to Solidity, encompassing 25 tasks of varying difficulty. Each task includes corresponding tests compatible with Hardhat, a popular Ethereum development environment, facilitating accurate compilation and testing of the generated code. The evaluation metrics, pass@1 and pass@3, measure the success of the model on initial attempts and across multiple trials, providing insight into accuracy and problem-solving capabilities.
Goals of Using AI Models in Smart Contract Development
By introducing these benchmarks, SolidityBench seeks to advance AI-assisted smart contract development. It encourages the creation of more sophisticated and reliable AI models while providing developers and researchers with valuable insights into the current capabilities and limitations of AI in Solidity development.
The benchmarking toolkit aims to advance IQ Code’s EVMind LLMs and also sets new standards for AI-assisted smart contract development in the blockchain ecosystem. The initiative hopes to address a critical need in the industry, where demand for secure and efficient smart contracts continues to grow.
AI developers, researchers, and enthusiasts are invited to explore and contribute to SolidityBench, which aims to drive continuous improvement of AI models, promote best practices, and advance decentralized applications.
Visit the SolidityBench leaderboard on Hugging Face to learn more and start comparing Solidity generation models.