




*Disclaimer: None of this constitutes an offense against any particular customer. It is very likely that each client, and perhaps even the specification, has its own oversights and bugs. Eth2 is a complicated protocol and the people implementing it are only human. The purpose of this article is to highlight how and why risks are mitigated.*
With the launch of the Medalla testnet, people were encouraged to experiment with different clients. And from the genesis, we understood why: the Nimbus and Lodestar nodes were unable to cope with the workload of a full test network and remained stuck. (0)(1) As a result, Medalla failed to finalize during the first half hour of its existence.
On August 14, the Prysm nodes lost track of time when one of the time servers they were using for reference suddenly jumped a day into the future. These nodes then began creating blocks and attestations as if they also existed in the future. When the clocks on these nodes were corrected (either by updating the client or because the time server returned to the correct time), those that had disabled the default outage protection had their stakes reduced .
What exactly happened is a bit more subtle, I highly recommend reading Raul Jordan’s account of the incident.
Clock Breakdown – The Worsening
By the time Prysm nodes began time traveling, they made up approximately 62% of the network. This meant that the block finalization threshold (>2/3 on a chain) could not be reached. Worse yet, these nodes couldn’t find the channel they were expecting (there was a 4 hour “gap” in the history and they all jumped at slightly different times) and therefore flooded the network with short forks as they had guessed. “missing” data.
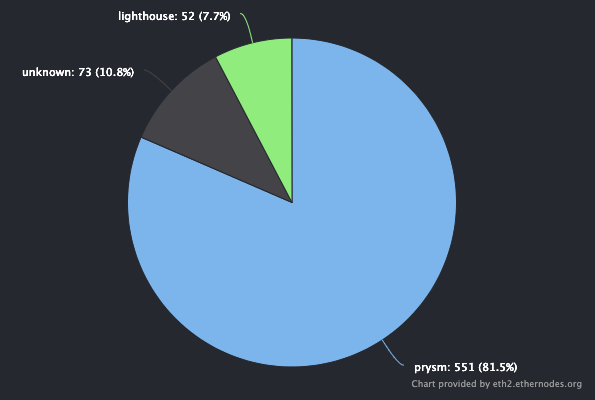
Prysm currently represents 82% of Medalla nodes 😳! (ethernodes.org)
At this point, the network was flooded with thousands of different guesses about what the head of the channel was and all clients were starting to buckle under the increased workload of determining which channel was the correct one. This led to nodes falling behind, having to synchronize, running out of memory, and other forms of chaos, making the problem worse.
Ultimately, this was a good thing, because it allowed us to not only solve the fundamental problem with clocks, but also test clients under conditions of massive node failure and network load. That said, this failure shouldn’t have been so extreme, and the culprit in this matter was Prysm’s dominance.
Shilling Decentralization – Part I, it’s good for eth2
As I discussed previously1/3 is the magic number when it comes to asynchronous and safe BFT algorithms. If more than a third of validators are offline, epochs can no longer be finalized. So, as the chain grows, it is no longer possible to point to a block and guarantee that it will remain part of the canonical chain.
Shilling Decentralization – Part II, it’s good for you
Where possible, validators are incentivized to do what is good for the network and are not simply asked to do something because it is the right thing to do.
If more than a third of the nodes are offline, the penalties for offline nodes start to increase. This is called the inactivity penalty.
This means that as a validator, you want to try to make sure that if something is going to take your node offline, it’s unlikely to take many other nodes offline at the same time.
The same goes for cuts. While there is always a chance that your validators will be cut due to a specification or software error/bug, the penalties for simple cuts are “only” 1 ETH.
However, if many validators are deleted at the same time as you, the penalties can reach 32 ETH. The point where this happens is once again the magic 1/3 threshold. (An explanation of why this is the case can be found here).
These incentives are called liveness anti-correlation and security anti-correlation respectively, and are very intentional aspects of eth2’s design. Anti-correlation mechanisms incentivize validators to make decisions that are in the best interest of the network, by linking individual sanctions to each validator’s impact on the network.
Shilling decentralization – Part III, the figures
Eth2 is implemented by many independent teams, each developing independent clients according to the specification written primarily by the eth2 research team. This ensures that there are multiple client implementations of beacon nodes and validators, each making different decisions regarding technology, languages, optimizations, tradeoffs, etc. required to create an eth2 client. This way, a bug in any layer of the system will only impact those running a specific client, not the entire network.
If, in the Prysm Medalla timing bug example, only 20% of the eth2 nodes were running Prysm and 85% of the people were online, then the inactivity penalty would not have been applied to the Prysm nodes and the issue could have be resolved. with only minor penalties and a few sleepless nights for the developers.
In contrast, because many people were using the same client (many of whom had cut protection disabled), between 3,500 and 5,000 validators were removed in a short period of time.* The high degree of correlation means that the reductions were d ‘around 16 ETH. for these validators because they were using a popular client.
* At the time of writing, the cuts are still rolling in, so there is no definitive figure yet..
Try something new

Now is the time to experiment with different clients. Find a client that a minority of validators use (you can check the distribution here). Lighthouse, Teku, NimbusAnd Prism are all reasonably stable at the moment while North Star quickly catch up.
Most importantly, TRY A NEW CUSTOMER! We have the opportunity to create a healthier distribution on Medalla in preparation for a decentralized mainnet.